

 分享至
分享至



干貨 | 代謝組數據預處理(三): 必看!數據Normalization方法選擇指南

【點擊圖片即可跳轉報名】
在對代謝組學數據分析之前,我們常常需要根據數據量綱的不同以及分析方法的需要對數據進行各種預處理,也即數據規范化(Normalization)處理,有些學者稱為標準化(Standardization)處理。數據規范化的目的主要有以下幾種:一是讓數據無量綱化,使不同性質的變量具有可比性;二是將不同數量級的變量數據經過不同的轉換(transform)至合適范圍,避免大值變量掩蓋小值變量的波動;三是可以使數據總體符合正態分布以方便參數檢驗;此外,還可以通過歸一化處理使數據分布均勻以方便作圖展示等。
01
數據Normalization的定義
數據Normalization,在我們代謝組學中,指的是通過對多個樣本,多個代謝物的定量數據進行一系列的中心化,縮放,以及轉換操作,減少數據集的噪聲干擾,強調其生物學信息,使其適用后續的統計分析方法,并改善其生物學解釋性。
簡單來說,就是對代謝數據集進行一些改變,把數據拉到一個特定范圍里,使之變得更有統計意義。
02
數據Normalization的必要性
我們通過來一組實際數據來看一下:

注:該數據來自本公司實際項目數據的子集,數據已進行了脫敏處理,代謝物?ID,樣本名均進行了替換。
通過以上數據可以明顯看出,代謝數據有著典型的高維度、高噪聲等特性,并且不同代謝物或者樣本間,普遍存在著數量級的差異。例如:表格中標記出來的代謝物MW0006,在6 個樣本中,就存在 1000多倍的差異,與Met0009的生物學相關性并不成比例。
此外,很多統計分析方法,對數據的分布較為敏感,統計的效力通常會集中于那些含量高或者倍數變化較大的代謝物之上,然而真正起到作用的很可能是那些濃度低的代謝物。因此,針對不同的統計分析方法,進行合理的數據Normalization是十分有必要的。
03
數據Normalization的方法
組學分析中常見的方法,大致可以歸為以下三個類別:
中心化(Centering)
中心化(Centering):即將所有數據減去平均值,讓數據分布在0值左右而非均值左右,聚焦于數據的差異;
縮放(Scaling)
縮放(Scaling):指將數據統一乘或者除一個因子,以消除數量級差異,有多種不同的縮放方法適應不同的分析需求;
轉換(Transformation)
轉換(Transformation):即進行Log或者Power變換,以消除異質性;
Berg等人在2006年將這三類方法進行了總結:

現對其進行解釋和補充如下:
Centering:常被稱為中心化,將數據從均值附近變換到0值附近;對存在異方差的數據處理效果不佳;
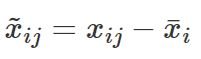
AutoScaling:常被稱為零值標準化,Z-score標準化或UV(unit variancescaling)等;將數據變成均值為0,方差為1的數據集;將變化集中在代謝物之間的相關性;對噪聲信號敏感,這個方法被廣泛的使用在許多機器學習算法中(例如:支持向量機、邏輯回歸和類神經網絡分析);

Min-MaxScaling:離差標準化,常被翻譯為歸一化,將數據縮放到[0,1]區間;對異常值敏感;

RangeScaling:比較變化量相對于變化范圍的比例以及變化方向;對測量誤差和異常值敏感;

ParetoScaling:相對AutoScaling在一定程度上保留了數據的原始結構,所得結果與原始數據更接近,但對大的倍數差異較敏感;

VastScaling:關注變動小的代謝物,需要特定的群體才有較好的效果;可以進行有監督分析;

LevelScaling:比較變化量相對均值的比例,適合用來發現生物標志物;對誤差敏感;

LogTransformation:消除異方差以及大的倍數差異影響,是數據線性化;代謝組學數據一般都呈現一個偏態分布(右偏),所以需要用一個合適的轉換來使得數據的分布變得對稱一些。若是數據中有0或負值,可以給全部數據加上一個數轉換為正數,所以常用log(1+x)來計算;

PowerTransformation:可以消除異方差影響,是數據線性化;選擇合適的root 很重要。

總峰面積歸一化:單一樣本的單一代謝物值/該樣品所有代謝物的總和,即把絕對值含量轉換成每個代謝物占樣品中總代謝物含量的比例來計算。此方法是較為常用的尿液代謝組學歸一化方法。
共峰面積歸一化:單一樣本的單一代謝物值/所有樣品該代謝物的總和,該方法相較于總峰歸一化排除了僅出現在個別樣本中的特殊變量對可用信號峰的干擾,增加了歸一化的準確性。
肌酐歸一化:肌酐(creatinine)是一種低分子量的含氮物質,正常機體每天通過尿液排出的肌酐量是恒定的,不會受尿量等因素的影響,因它常被用于尿液代謝組學研究中的校準指標,即用每個變量的峰面積除以相應肌酐的峰面積。
PQN:概率熵歸一化(ProbabilisticQuotientNormalizaton),也是一種常用的尿液代謝組數據歸一化方法。該算法的前提假設是大部分代謝物在樣本間是保持不變的,只有部分代謝物是差異表達的,不適用于存在大量差異表達代謝物的數據集。
04
Normalization方法的選擇
前面我們提到過,有些統計分析對規范化方法非常敏感,其中PCA分析就是一個典型。接下來我們對2個實際數據集進行不同的規范化處理,然后進行PCA分析,來看看不同方法的效果。(數據來自本公司實際項目數據,對于代謝物ID,樣本名,分組名等信息已進行了脫敏處理,并刪除了部分數據。)
下圖選擇了代謝組數據分析中最常見的5種方法的結果進行展示。
數據集1分為2個組,3個地域群體,共221個樣本,加上13個mix,檢測出600+個代謝物。

上圖中一共有四個樣本分組和一個mix分組;樣本分組中,AE(橙色),AS(橄欖色),AW(綠色)是同一組群體在不同地域的樣本;BW(藍色)是另一組群體,但是和AW在同一個地域;mix分組(粉色)應該聚成一個點。從上圖中可以發現,Autoscaling(標準化)和兩種轉換方法明顯效果較好。
數據集2為多個個體以及個體不同組織共31個樣本加上3個mix,檢測出600+個代謝物。

上圖中一共有四個樣本分組和一個mix分組;A(橙色)是一個組織,B1(橄欖色),B2(綠色)是同一個組織不同部位;C(藍色)是另一個組織;mix分組(粉色)應該聚成一個點;通過上圖可以看出,同樣是Autoscaling(標準化)和兩種轉換方法明顯效果較好,并且Log轉換方法效果最好。2018年,李霜發表的文章[2]中統計了在代謝組相關文獻中,使用率最高的規范化方法,就是Log轉換,可見Log轉換方法的適應性最廣。
兩組不同的數據,兩種Transformation方法和AutoScaling方法都取得了不錯的效果。雖不能代表代謝組數據的全部情況,但是也足以說明這三種方法的效果。此外,在我們沒有放出的圖片中,ParetoScaling有著和 AutoScaling方法相差無幾的效果,其次是RangeScaling方法。
事實上,從結果來選擇使用方法是不可取的,因為不管是哪種方法,之所以能夠獲得較好的結果,都是基于代謝組數據的本質特點。常見的廣泛靶向代謝組和非靶向代謝組數據具有高維,高噪,稀疏,右偏的特點;而PCA要求數據是同方差數據,對異方差敏感,對線性性敏感;上述幾種效果較好的規范化方法剛好適合PCA分析。如果換一種統計方法,那么Normalization方法也需要根據實際情況進行調整。因此,在分析時可以多嘗試一些規范化的方法,結合具體的實驗內容、目的進行多次的調試以實現所期望的目標。
參考文獻:
1.van den Berg, R.A., Hoefsloot, H.C., Westerhuis, J.A. et al. Centering, scaling, and transformations: improving the biological information content of metabolomics data. BMC Genomics 7, 142 (2006).
2.李霜. 基于代謝組學的數據標準化方法的綜合評價[D].重慶大學,2018.
往期精彩:
●干貨 | 代謝組數據預處理(一):缺失值填充,你真的會嗎?
●干貨 | 代謝組數據預處理(二):巧踢離群值,讓你的數據會說話

客服微信:metware888
咨詢電話:027-62433042
郵箱:support@metware.cn
網址:www.metware.cn
我就知道你“在看”










